This blog post describes improvements to the TensorRT pipeline for desktop and embedded GPUs with DeepDetect.
Full CUDA pipeline for real time inference
DeepDetect helps with creating production-grade AI / Deep Learning applications with ease, at every stage of conception. For this reason, there’s no gap between development and production phases: we do it all with DeepDetect.
This allows working from the training phase to prototyping an application, up to final production models that can run at optimal performances and perform inference in real time.
This methodology has several advantages:
- It removes the development to production difficulties since it preserves the input pipelines and ensures models retain their accuracy.
- DeepDetect leverages dedicated optimization automatically for the underlying hardware, whether GPU, desktop CPU or embedded.
- Production-grade inference is readily available, without any changes, API calls remain identical.
This post focuses on the third point, and most especially GPU inference performances. And most especially the type of applications with real-time requirements.
At Jolibrain we see many very different industrial applications with this use-case, mainly in two categories:
Applications with a real-time requirements, such as virtual try-ons and virtual/augmented reality. These applications typically mix object detectors and GANs, requiring multi-model real-time inference.
Applications with very high throughput requirements. These industrial applications need processing points clouds, and other types of sensor outputs at very high speeds, e.g. 5000 frames per second.
For these applications, DeepDetect embeds a TensorRT backend to run models on NVidia GPUs with x2 or x3 performance gains. This is the best that can be done at the moment. TensorRT is efficient but it’s fair to note that it is not easy to setup properly and optimization comes with many, many caveats, such as unsupported layers, data types, all hardware dependent sometimes. For these reasons, we’ve automated it all into DeepDetect, so that these difficulties are abstracted away.
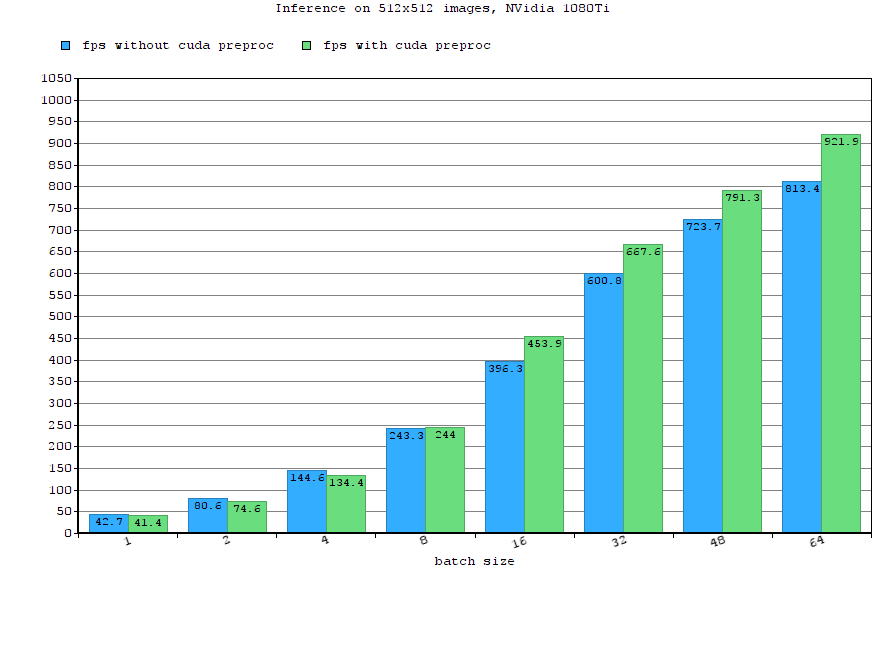
This has been efficient for a while, but as inference itself gets more optimized, and model prediction time decreases accordingly, the full input pipeline sometimes becomes the bottleneck, and needs to be optmized as well for even better efficiency.
In most of applications the raw data is not passed to the model directly, and some preprocessing is needed. This is typically true for images, where resizing, normalizing and format conversion are standard operations before the data hit the models.
These preprocessing steps can take an uneven amount of time, until they even become a bottleneck, most especially on edge/embedded devices with low computational power.
Preprocessing can be improved by using hardware acceleration. Most of the usual preprocessing operations are already implemented in OpenCV CUDA, and thus it’s been recently added to DeepDetect preprocessing pipelines.