DeepDetect now has support for one of the promising new architectures for computer vision, the Visformer. This short post introduces the current trends around novel neural achitectures for computer vision, and shows how to experiment with the Visformer in DeepDetect in just under a few minutes.
The Visformer mixes the convolutional approach with full-attention transformer layers in an hybrid approach with good properties: the FLOPs/accuracy ratio is 3x better than that of a ResNet-50 with a 2% increase in accuracy.

This is what’s expected on paper, and in this post we see how to use the Visformer with DeepDetect and report on how it behaves in practice in a low data regime.
Research on Transformer neural architectures for vision continues
As previously discussed with DeepDetect, there’s a new breed of computer vision neural models in the making. In brief terms, these architectures are tentative replacements for the now common convolutional architectures for vision. The new trend swaps the convolutional layers with elements of the Transformer architectures originally developed for NLP.
Since then academic research has succeeded in uncovering yet new and improved architectures, with DEiT and related works such as T2T, Swin, LeViT and the Longformer.
The main drawback of these approaches is much longer training (up to x10) and large volumes of data complemented by heavy data augmentation. In the Visformer paper this special requirement is refered to as the elite performance setup as opposed to the more traditional base setup of Imagenet with less heavy augmentation.
Worth noting, yet a new trend is emerging that reports still excellent results replacing the Transformer self-attention layers with straight MLPs and reported independently by Luke Melas-Kyriazi and Google. This is a trend we are following at Jolibrain and that we may report upon in more details soon.
So in practice, the transformer-based architectures do not yield drop-in replacements to the existing relatively well-behaved convolutional networks. However, they remain very competitive in terms of computation requirements (aka FLOPs), high accuracy and low inductive bias.
Hybrid convolutional + transformer architectures for the win
A rational direction is then to consider hybrid architectures that mix convolutional layers where they are most convenient with transformer self-attention layers where their impact is maximal.
As such, there’s a tribe of recent works from the academia in this direction. As usual when mixing the best of both worlds, some papers do report both higher accuracy than pure transformer architectures for vision with basic training setups.
In this hybrid vein, there’s the Visformer along with the bottleneck transformer and standalone self-attention.
In our opinion the Visformer proposes the simplest, most efficient architecture along with a clear and well documented empirical justifications.
For this reason it’s been recently implemented as readily usable template in DeepDetect with its C++ torch backend.
The Visformer architecture
Very basically, the Visformer makes a series of small changes to the ViT/DeiT architectures by identifying paintpoints when training in both the base and elite setups.
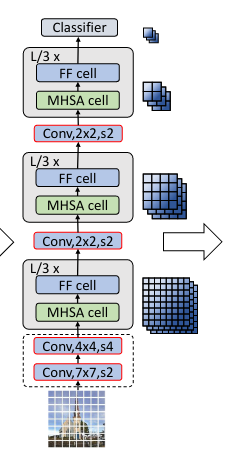
Among these changes, most importantly, is the conservation of locality at the image patch level, the use of 1x1 convolutinos and of global pooling, while removing the specialized token introduced by ViT.
The result are tow novel architectures with very good FLOPs/accuracy trade-offs. This means the FLOPs are similar to a ResNet-18 but with the accuracy of a ResNet-50. A good property in practice. So below we look at what we get in a realistic, low data regime, setup.
Experimenting with Visformer in DeepDetect

Both Visformer-tiny and Visformer-S (’S’ stands for small) are available in DeepDetect v0.17.0.
To train a Visformer model with DeepDetect is very easy:
- Use the
torchbackend - Set the neural architecture template:
"template":"visformer" - Use the template parameters to select between Visformer-tiny and Visformer-S:
"template_params":{"visformer_flavor":"visformer_tiny"}or"visformer_flavor":"visformer_small". Tiny is the default is thetemplate_paramsare omitted.
We take a very simple, low data regime, cats vs dogs classification task that we train from scratch and we compare the Visformer to ResNet-18 and ViT-tiny architectures. Importantly, we do train all networks from scratch, thus revealing their true capability in a low to regular data regime.
As can be seen, ViT does not work in such low data regime, an issue that is clearly fixed by the Visformer. Now, Visformer in low data regime remains slightly less competitive than ResNet-18, but closes the gap almost fully. ResNet-18 and Visformer-tiny have similar FLOPs and parameters.
Below is a full example:
Create a Visformer service
curl -X PUT http://localhost:8080/services/testvisformer -d ' { "description": "image", "mllib": "torch", "model": { "create_repository": true, "repository": "/path/to/cats_dogs_visformer_tiny" }, "parameters": { "input": { "connector": "image", "db": true, "height": 224, "mean": [ 128, 128, 128 ], "std": [ 256, 256, 256 ], "width": 224 }, "mllib": { "gpu": true, "gpuid": 0, "nclasses": 2, "template": "visformer", "template_params": { "dropout": 0.1, "visformer_flavor": "visformer_tiny" } } }, "type": "supervised" } 'Train a Visformer model
curl -X POST http://localhost:8080/train -d ' { "async": true, "data": [ "/path/to/data/dogs_cats/" ], "parameters": { "input": { "db": true, "mean": [ 128, 128, 128 ], "shuffle": true, "std": [ 256, 256, 256 ], "test_split": 0.1 }, "mllib": { "crop_size": 224, "cutout": 0.1, "finetune": false, "geometry": { "pad_mode": 1, "persp_horizontal": true, "persp_vertical": true, "prob": 0.2, "zoom_in": true, "zoom_out": true }, "mirror": true, "nclasses": 2, "net": { "batch_size": 128, "test_batch_size": 128 }, "resume": true, "solver": { "base_lr": 3e-05, "iter_size": 4, "iterations": 20000, "solver_type": "ADAM", "test_interval": 250 } }, "output": { "measure": [ "f1", "acc", "cmdiag" ] } }, "service": "testvisformer" } '