OCR in the wild
DeepDetect Server and Platform come with everything ready to setup your own OCR solution. This application page describe how to get running in minutes.
An example of the final output:

Results on Paris street sign.
This OCR solution works in two main steps:
- Text detection from images uses a word detection deep learning model that outputs bounding boxes around text
- OCR uses a multi-word deep learning model that takes the relevant image crops from the previous step as input and predicts a text string
This setup is similar to the OCR setup used by Facebook and called Rosetta. We borrow from them the image below that summarizes the process:
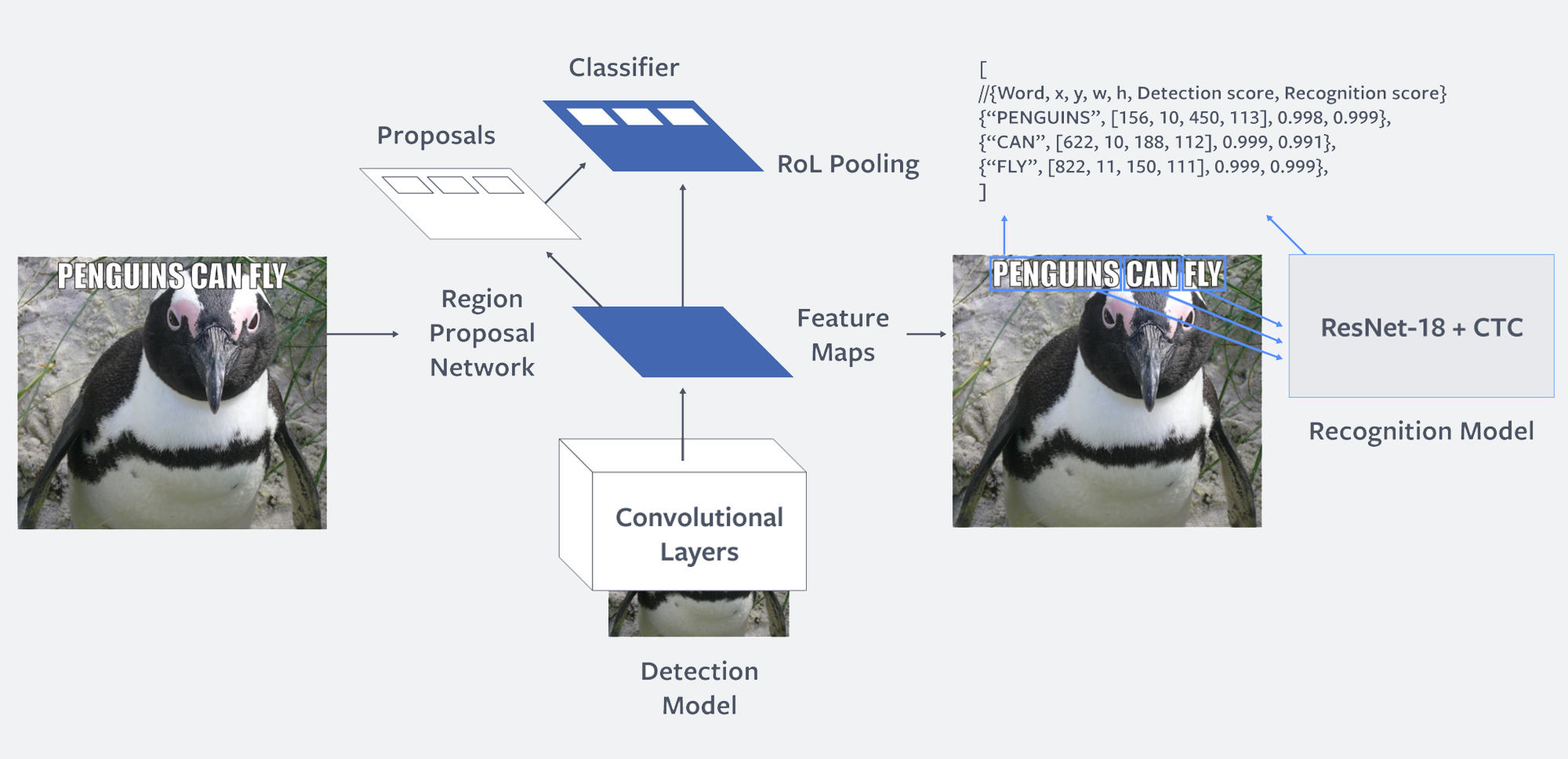
A two model architecture: 1/ detect words; 2/ OCR on word image crops. [Image borrowed from Rosetta], with the difference that DeepDetect is using a Single Shot Detector (SSD) and uses image crops instead of feature maps.
Setup
We start by setting up the DeepDetect Server, we assume a GPU setup with Docker that can be adapted as needed.
Then we setup the required models.
Word detection model
We use the DeepDeteect word detection deep learning model. Follow installation instructions, then test with the call below:
curl -X POST 'http://localhost:8080/predict' -d '{
"data": [
"https://deepdetect.com/img/apps/short-paris-street-signs.jpg"
],
"parameters": {
"input": {},
"mllib": {
"gpu": true
},
"output": {
"bbox": true,
"confidence_threshold": 0.2
}
},
"service": "word_detect"
}
'
or equivalently in Python using dd_client.py :
from dd_client import DD
from IPython.display import Image
import cv2
import numpy as np
filepath = (https://deepdetect.com/img/apps/short-paris-street-signs.jpg)
bbox_pad = 0.015 # ratio before cropping
img = Image(filepath)
arr = np.asarray(bytearray(img.data), dtype=np.uint8)
img_arr = cv2.imdecode(arr, cv2.IMREAD_COLOR)
ysize, xsize, _ = img_arr.shape
dd = DD("localhost", 8080)
dd.set_return_format(dd.RETURN_PYTHON)
detection = dd.post_predict(
"word_detect",
data=[filepath],
parameters_input={},
parameters_mllib={},
parameters_output={"confidence_threshold": 0.2, "bbox": True},
)
# Optional: getting the list of bbox to easily draw them later on
list_bbox = detection["body"]["predictions"][0]["classes"]
bbox_list = []
for elt in list_bbox:
xmin = int(elt["bbox"]["xmin"])
xmax = int(ceil(elt["bbox"]["xmax"]))
ymin = int(elt["bbox"]["ymax"])
ymax = int(ceil(elt["bbox"]["ymin"]))
deltax = int(bbox_pad * (xmax - xmin))
deltay = int(bbox_pad * (ymax - ymin))
xmin, xmax = max(0, xmin - deltax), min(xsize, xmax + deltax)
ymin, ymax = max(0, ymin - deltay), min(ysize, ymax + deltay)
bbox_list.append((xmin, xmax, ymin, ymax))
On the shell, the curl call yields results that look like:
{
"body": {
"predictions": [
{
"classes": [
{
"bbox": {
"xmax": 304.4400939941406,
"xmin": 160.37918090820312,
"ymax": 107.0147705078125,
"ymin": 130.6460723876953
},
"cat": "1",
"prob": 0.9976158142089844
},
...
{
"bbox": {
"xmax": 315.3223571777344,
"xmin": 296.52557373046875,
"ymax": 93.34095764160156,
"ymin": 107.23853302001953
},
"cat": "1",
"last": true,
"prob": 0.49438440799713135
}
],
"uri": "https://deepdetect.com/img/apps/short-paris-street-signs.jpg"
}
]
},
"head": {
"method": "/predict",
"service": "word_detect",
"time": 8095.0
},
"status": {
"code": 200,
"msg": "OK"
}
}
And visualizing the boxes with a short Python script:
from matplotlib import patches
fig, ax = plt.subplots(figsize=(20, 15))
ax.imshow(img_arr[:, :, ::-1])
for (xmin, xmax, ymin, ymax), prediction in zip(
bbox_list,
sorted(ocr["body"]["predictions"], key=lambda elt: int(elt["uri"])),
):
rec = patches.Rectangle((xmin, ymin),xmax - xmin,ymax - ymin,
linewidth=2,
edgecolor="red",
facecolor="none",
)
ax.add_patch(rec)
ax.set_xticks([])
ax.set_yticks([])

Text detection on Paris street sign.
OCR model
We use the DeepDetect multi-word deep learning model model. Follow installation instructions, then test with the call below:
curl -X POST 'http://localhost:8080/predict' -d '{
"data": [
"https://deepdetect.com/img/apps/ocr_1.png"
],
"parameters": {
"input": {},
"mllib": {
"gpu": true
},
"output": {
"blank_label": 0,
"confidence_threshold": 0,
"ctc": true
}
},
"service": "word_ocr"
}'

{
"body": {
"predictions": [
{
"classes": [
{
"cat": "cambon",
"last": true,
"prob": 1.0
}
],
"uri": "https://deepdetect.com/img/apps/ocr_1.png"
}
]
},
"head": {
"method": "/predict",
"service": "word_ocr",
"time": 429.0
},
"status": {
"code": 200,
"msg": "OK"
}
}
Detect text and read words
Now putting it together efficiently, the bounding box crops are turned into base64 encoded in-memory images, and passed to the OCR model in batches. This is much faster than processing single boxes, especially on GPU.
The steps are as follows: - Call on the word detection model - Crop the boxes around text - Turn the crops into base64 - Pass the boxes to the OCR model
Python script for the base64 encoding and OCR processing:
from math import ceil
import base64
list_bbox = detection["body"]["predictions"][0]["classes"]
bbox_list = []
list_base64 = []
for elt in list_bbox:
xmin = int(elt["bbox"]["xmin"])
xmax = int(ceil(elt["bbox"]["xmax"]))
ymin = int(elt["bbox"]["ymax"])
ymax = int(ceil(elt["bbox"]["ymin"]))
bbox_list.append((xmin, xmax, ymin, ymax))
status, array = cv2.imencode(".png", img_arr[ymin:ymax, xmin:xmax])
list_base64.append(base64.b64encode(array.tostring()).decode())
ocr = dd.post_predict(
"word_ocr",
data=list_base64,
parameters_input={},
parameters_mllib={},
parameters_output={"ctc": True, "blank_label": 0},
)
Results can be visualized with:
from matplotlib import patches
# from operator import attrgetter
fig, ax = plt.subplots(figsize=(20, 15))
ax.imshow(img_arr[:, :, ::-1])
for (xmin, xmax, ymin, ymax), prediction in zip(
bbox_list,
sorted(ocr["body"]["predictions"], key=lambda elt: int(elt["uri"])),
):
rec = patches.Rectangle((xmin, ymin),xmax - xmin,ymax - ymin,
linewidth=2,
edgecolor="red",
facecolor="none",
)
ax.add_patch(rec)
ax.text(xmin,ymin,
prediction["classes"][0]["cat"],
color="red",
bbox=dict(facecolor="white", edgecolor="red", boxstyle="round,pad=.5"),
)
ax.set_xticks([])
ax.set_yticks([])
Results on Paris street sign.
As a result, for every image, there’s now:
- Bounding box coordinates around pieces of text
- A string value for every of the boxes
Conclusion
DeepDetect Server and Platform come with built-in models to easily test and build a preliminary OCR solution. By gathering training sets for your own tasks, you can improve on the solution above for your own needs and requirements.